Published on datamastery.com.au | Part of the Enterprise AI in Regulated Environments series
Introduction
AI pilot projects tend to succeed. They operate with curated datasets, limited users, and close human supervision. The variables are controlled, the stakes are manageable, and the outputs are reviewed.
Production is different.
In production, AI systems interact with dynamic data, heterogeneous users, external APIs, and evolving organisational processes. Systems that performed well in pilots encounter failure modes that were never visible in controlled conditions – hallucinations grounded in the wrong documents, retrieval crossing security boundaries it was never meant to cross, agentic workflows triggering actions without adequate human review.
The core challenge facing enterprise AI in 2026 is no longer capability. It is control.
Responsible scaling requires more than policy statements or ethics guidelines. It requires governance mechanisms embedded directly into the architecture of AI systems – operating continuously, not as a pre-deployment checkpoint.
This article sets out a practical model for what that looks like.
The insight from AILovesData Austin
Discussions at AILovesData Austin (formerly Data Science Salon) surfaced a theme that runs through most serious enterprise AI conversations right now: the gap between governance as documentation and governance as operational discipline.
Many organisations have already published responsible AI policies. Some have formed ethics committees. These structures have value – but they rarely address what happens once an AI system is deployed at scale, under real load, with real users making unexpected requests.
Policies define intentions. Architecture enforces them.
The “Scaling Responsibly” discussion reinforced that governance must operate as a continuous lifecycle discipline – embedded across data pipelines, model management, inference systems, and runtime monitoring. Not added later. Designed in from the start.
The AI Governance Stack
A useful way to think about production governance is as a layered stack of technical enforcement capabilities. Each layer addresses distinct risks. Weakness at any layer creates vulnerabilities that may not be visible until the system is operating at scale.
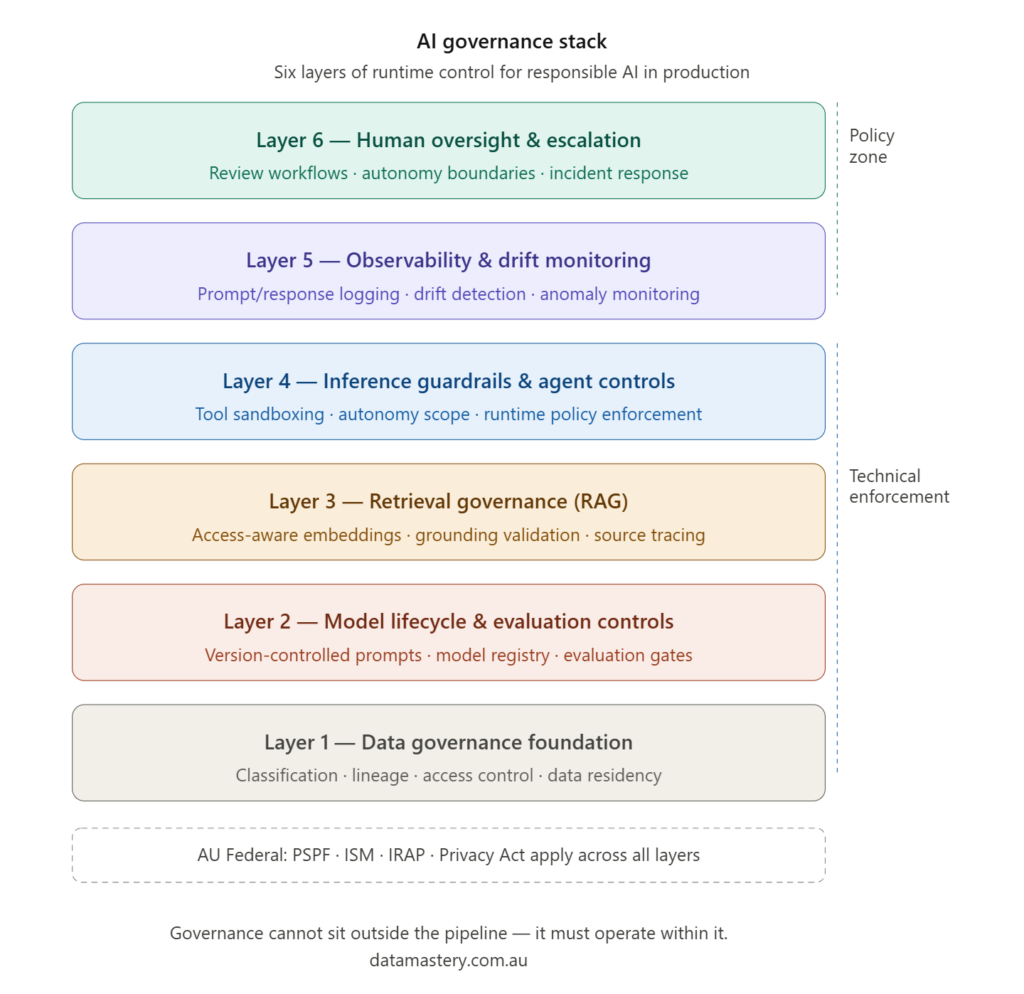
Layer 1 – Data governance foundation
All AI systems depend on data. Governance must begin at the point data enters the system.
Classification-aware ingestion ensures data is categorised for sensitivity and regulatory requirements before it enters any pipeline. Data lineage must be traceable – organisations need the ability to connect outputs back to their source data, particularly for audit and regulatory purposes.
In RAG architectures, the specific risk is at the embedding boundary. Documents converted into vector embeddings and stored in a vector database sit outside traditional access control frameworks. Without explicit controls, sensitive data embedded during indexing may become retrievable by users who should not have access to it. Access-aware retrieval – where role-based access controls propagate into the vector store and are enforced at query time – is not optional in regulated environments. It is foundational.
Data residency and segmentation controls are also relevant here, particularly in Australian federal contexts where data sovereignty obligations may restrict where data is processed and stored.
Layer 2 – Model lifecycle and evaluation controls
AI systems do not stay static. Models are retrained, prompts are refined, system instructions evolve. Without structured lifecycle management, production systems drift – often silently.
Prompts should be treated as deployable artefacts and managed within version-controlled repositories. This ensures that changes to system behaviour are traceable and reversible. A model registry should catalogue all production models, including metadata about training datasets, version history, and approval status.
Evaluation cannot be limited to offline benchmarking before release. Production systems need ongoing evaluation through multiple mechanisms: automated grounding checks, LLM-based evaluation, human scoring, and A/B testing of model behaviour over time. Promotion of model or prompt updates into production should be gated against defined risk thresholds, not treated as routine deployment.
Layer 3 – Retrieval governance
RAG systems introduce complexity that traditional software governance models are not designed for. The retrieval layer sits between the data foundation and the inference system – and it is where many governance failures in real-world deployments originate.
Retrieval grounding validation checks that generated responses remain anchored in retrieved documents. Context leakage monitoring ensures sensitive content from one user’s retrieval context does not appear in another’s. Source traceability connects generated outputs back to the specific documents that informed them — a requirement for audit and accountability in high-stakes settings.
In document-heavy environments like Australian federal agencies – where systems like TRIM, Objective, and SharePoint hold sensitive records with complex access structures – retrieval governance is particularly important and particularly difficult.
Layer 4 – Inference guardrails and agent controls
The rise of agentic AI systems – systems that call tools, chain decisions, and execute multi-step workflows – introduces a different category of risk. These systems can call external APIs, trigger transactions, access and modify enterprise data, and take actions with real operational consequences.
Governance at this layer requires explicit execution boundaries. Tool-call sandboxing restricts which external systems an AI can interact with and under what conditions. Autonomy scope should be defined by task class – different task types warrant different degrees of autonomy, and the boundary between autonomous execution and human review should be explicit and enforced, not implied. Deterministic fallback mechanisms handle situations where model outputs fall outside acceptable parameters. Runtime policy engines enforce rules dynamically during execution rather than relying on pre-deployment documentation.
Layer 5 – Observability and drift monitoring
Once an AI system is in production, governance shifts toward continuous monitoring. This is where observability becomes a governance control, not just an operational tool.
Structured logging of prompts and responses provides the audit trail required for both security investigation and regulatory reporting. Retrieval grounding validation should run continuously, not just at evaluation time. Drift detection monitors for changes in embedding representations, data distributions, or output patterns that may indicate degrading performance. Security monitoring should cover prompt injection attempts, abnormal access patterns, and potential data exfiltration via model outputs.
The principle is simple: if outputs cannot be traced, logged, and analysed, they cannot be trusted in high-accountability environments. Observability is the detective control layer of the AI governance stack.
Layer 6 – Human oversight and escalation
Human oversight is not a checkbox. It is an operational control mechanism.
Governance at this layer requires defined thresholds for escalation – clear criteria for when AI decisions require human review before action. Review workflows must be operational, not theoretical. Accountability ownership must be explicit: someone is responsible for AI system behaviour, and that responsibility must be defined before the system goes live.
In Australian federal environments, this has additional weight. Decisions that carry ministerial risk, affect individual rights, or carry audit exposure cannot be delegated to autonomous AI systems without adequate human oversight. The accountability frameworks that govern public administration apply to AI-assisted decisions in the same way they apply to human ones.
The global regulatory context
Understanding where production governance sits in the broader regulatory landscape helps organisations design systems that are durable across jurisdictions.
The EU AI Act is the most advanced binding AI regulation globally. It introduces a risk-based framework: unacceptable, high, limited, and minimal risk categories – with significant compliance obligations for high-risk systems including mandatory risk management, data governance, logging, transparency, human oversight, and cybersecurity controls. Critically, the Act frames compliance as a lifecycle obligation, not a one-time assessment.
The NIST AI Risk Management Framework, which has significant influence in US enterprise settings, structures governance around four functions: Govern, Map, Measure, and Manage. It emphasises risk identification and iterative control rather than strict legal compliance, and it has been widely adopted as an operational governance model even outside the United States.
The United Kingdom’s principles-based approach – safety, transparency, fairness, accountability, and contestability -delegates enforcement to existing sector regulators rather than creating a single AI authority. It is lighter-touch than the EU model and explicitly designed to preserve flexibility for innovation.
Australia does not yet have an AI Act equivalent. Current governance relies on the AI Ethics Principles (voluntary), the Protective Security Policy Framework, the Information Security Manual, and existing privacy legislation. Government consultation processes are actively considering a risk-based framework that draws on EU and NIST approaches. For organisations deploying AI in federal environments, the practical implication is that PSPF and ISM controls must be satisfied today, and a more formal AI governance framework is likely in the medium term. Designing AI systems with the AI Governance Stack in mind prepares organisations for both.
What is converging across all major jurisdictions is this: risk-based classification, mandatory human oversight for high-risk systems, auditability and logging requirements, and governance across the full AI lifecycle. Organisations designing AI systems with these requirements in mind will be better positioned regardless of which specific framework becomes binding in their jurisdiction.
From documentation to architecture
The shift happening in AI governance mirrors a shift that occurred in cybersecurity over the past two decades. Security evolved from manual processes and policy documents into automated control systems embedded in infrastructure – firewalls, access management, monitoring pipelines, incident response automation. The policy still matters, but the control is technical.
AI governance is following the same trajectory. Responsible AI is not a governance committee meeting quarterly. It is access-aware retrieval, version-controlled prompts, evaluation pipelines, observability tooling, and defined human escalation paths – all operating continuously, across the full lifecycle of every AI system in production.
The organisations that treat governance as infrastructure will build AI systems that can be trusted at scale. The organisations that treat it as documentation will discover its limits in production.
Conclusion
Responsible AI is not achieved at the point of deployment. It is maintained through the operational lifetime of the system.
Governance must run continuously across data pipelines, model lifecycles, retrieval systems, inference controls, and runtime monitoring. It must be designed in before deployment, not retrofitted after failure.
The AI Governance Stack offers a practical lens for structuring that discipline -six layers of technical enforcement that together make AI systems auditable, controllable, and trustworthy in high-accountability environments.
The question for every organisation deploying AI at scale is not whether governance is required. It is whether governance will be engineered before deployment – or imposed after something goes wrong.
This article is part of the Data Mastery series on practical AI governance for enterprise and regulated environments. If your organisation is working through AI governance design, contact Data Mastery to discuss.
Author bio box
Vinnie Kura Delivery Lead | AI Governance & Secure AI Practitioner | Federal Digital Transformation | Cyber Security (UNSW)
Vinnie is a Canberra-based enterprise delivery lead with over a decade of experience across large-scale digital transformation programs in Australian federal government environments. He holds a Master of Cyber Security Operations from UNSW Canberra and writes on AI governance, secure deployment architecture, and the practical challenges of operationalising AI in regulated environments.
Conflict of interest / disclaimer line
The views expressed in this article are the personal views of the author and do not represent the views, positions, or policies of any current or former employer, client, or government agency. This content is published independently through Data Mastery and is intended for general informational and educational purposes only.