From Raw Documents to Explainable AI – Building Retrieval Systems from First Principles
By Data Mastery
Introduction: Why Document Intelligence Still Matters
Every organisation has documents. Policies, procedures, standards, reports, PDFs, and emails.
Yet most systems still treat documents as unstructured blobs of text , searchable but not truly understood.
In recent years, large language models (LLMs) have promised a shortcut: “Just feed the documents to an AI and ask questions.”
What is often missed, however, is that these systems are only as reliable as the information they retrieve. What has changed is not the volume of documents, but the expectation that systems should reason over information, not simply retrieve it. This expectation is what has driven interest in Retrieval-Augmented Generation (RAG), semantic search, and AI-powered assistants.
This article takes a different approach.
Instead of starting with models, prompts, or tools, we start with first principles:
- how text is prepared,
- how meaning is represented,
- how retrieval works,
- and why explainability is a data problem before it is an AI problem.
This foundation applies regardless of platform, tooling, or model choice.
The Mental Model: How Documents Become Knowledge
Before looking at implementations, it’s important to understand the conceptual pipeline behind almost every modern document intelligence system:
Raw Document
→ Clean Text
→ Chunks (sentences or sections)
→ Tokens (terms)
→ Numerical Representation (vectors)
→ Similarity & Retrieval
Every section in this article maps directly to one stage in this pipeline.
If you understand this flow, you understand the core of RAG, semantic search, and document intelligence — with or without an LLM.
Step 1: From Raw Documents to Clean Text
Raw documents are noisy. They include:
- formatting artefacts,
- headers and footers,
- page numbers,
- inconsistent casing,
- and irrelevant symbols.
Before any analysis is meaningful, text must be normalised.
Typical preparation includes:
- converting text to lowercase,
- removing non-semantic characters,
- normalising whitespace,
- preserving meaningful words and phrases.
Key insight:
Most AI failures originate from poor text preparation, not from poor models.
If this step is rushed or ignored, everything downstream becomes unreliable.
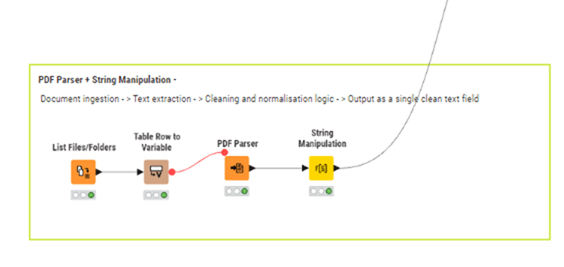
PDF Parser → String Manipulation (Text Cleaning)
The above inset demonstrates document ingestion, text extraction, and deterministic cleaning logic that produces a consistent, machine-readable text representation.
Step 2: Chunking – Where Meaning Actually Lives
A complete document is usually too large and too broad to reason over effectively.
Meaning almost always lives in:
- sentences,
- paragraphs,
- or logical sections.
Chunking transforms a document into smaller semantic units:
Document
├─ Sentence 1
├─ Sentence 2
├─ Sentence 3
Each chunk becomes easier to:
- compare,
- retrieve,
- and explain.
Key insight:
Retrieval systems do not retrieve documents.They retrieve relevant chunks of meaning.
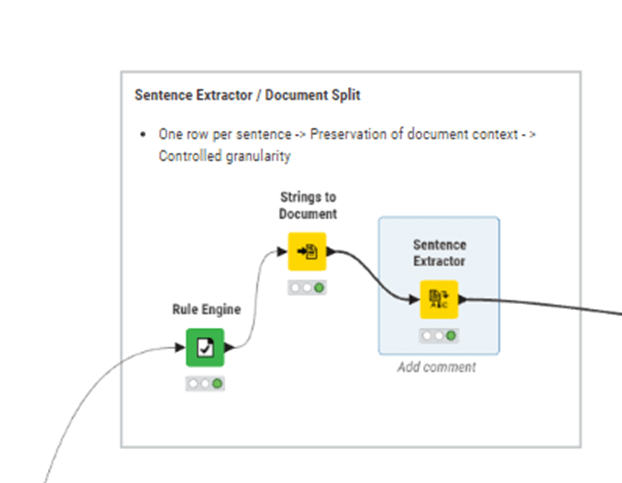
Sentence Extractor / Document Split
Each sentence becomes a discrete unit that can later be indexed, compared, and ranked.
Step 3: Tokenisation – Turning Language into Data
Machines do not understand sentences.
They operate on tokens.Tokenisation breaks text into its fundamental units — usually words or terms.
Example:
"essential eight assessment process guide"
↓
["essential", "eight", "assessment", "process", "guide"]
This is the moment where language becomes data: something that algorithms can operate on deterministically.
Tokenisation is not glamorous, but it is essential. Without it, there is no retrieval, no similarity, and no explainability.
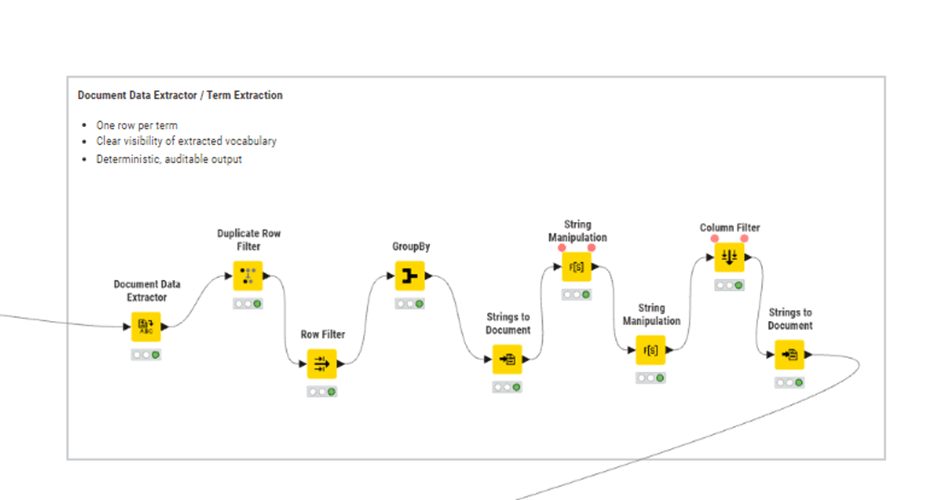
Term Extraction / Document Data Extractor
This step exposes the vocabulary explicitly, making the system auditable and inspectable.
Step 4: Bag-of-Words – The Foundation of Retrieval
The Bag-of-Words (BoW) model is often dismissed as outdated.
In reality, it remains one of the most important conceptual foundations in text analytics.
Bag-of-Words:
- builds a vocabulary,
- records the presence or frequency of terms,
- ignores word order,
- focuses on content rather than syntax.
Example representation:
| Term | Value |
| essential | 1 |
| eight | 1 |
| assessment | 1 |
| guide | 1 |
This is not “dumb” – it is explicit meaning expressed numerically.
Key insight:
Modern embeddings did not replace Bag-of-Words.They generalised it.
Understanding BoW makes embeddings easier to reason about, not harder.
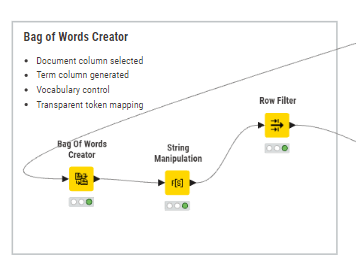
Bag-of-Words Creator
Vocabulary creation and term frequency are fully visible and reproducible.
Step 5: From Words to Vectors
Once words are represented numerically, similarity becomes possible.
A document is no longer text – it is a vector in mathematical space.
Example:
[1, 1, 1, 0, 1, 0, …]
This is the turning point where:
- relevance can be measured,
- similarity can be calculated,
- retrieval becomes systematic rather than heuristic.
Weighting techniques such as TF-IDF refine this further by emphasising informative terms and down-weighting common ones.

Document Vector Output
Each document or chunk is represented as a numerical vector suitable for similarity search.
Step 6: Why This Enables Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation relies on one principle:
The quality of generated answers depends on the quality of retrieved information.
Retrieval requires:
- clean text,
- consistent chunking,
- reliable vector representations.
Large language models sit on top of this pipeline, they do not replace it.
Key insight:
RAG is fundamentally a data engineering problem, not a model problem.
What RAG Is Not
RAG is not “uploading documents into an LLM.”
It is not prompt engineering.
It is not solved by choosing a bigger model.
Without trustworthy retrieval, generation has nothing reliable to build on.
Step 7: Explainability as a First-Class Feature
Because every transformation in this pipeline is explicit, the system can answer:
- Why was this document retrieved?
- Which terms contributed to relevance?
- How was similarity calculated?
Explainability does not come from the model.
It comes from understanding the data pipeline.
This is critical for trust, governance, and responsible AI adoption.
Tooling Note
The workflows shown here are implemented using visual analytics tools to make each transformation explicit and inspectable.
The same principles apply equally in code-based, distributed, or cloud-native environments.
The goal is not the tool , it is mastery of the underlying concepts.
Where This Goes Next
This article intentionally focuses on the retrieval foundation.
Future extensions include:
- TF-IDF weighting strategies,
- similarity search,
- embeddings and hybrid retrieval,
- and responsible integration of LLMs.
None of this work well without the fundamentals described here.
Conceptual RAG Lifecycle
The diagram below illustrates how documents are transformed into vectors, retrieved via similarity search, and used to ground generated responses in verifiable source material.


Final Thought
AI systems are only as intelligent as the data pipelines beneath them.
If you understand:
- how documents become vectors,
- why retrieval works,
- and where explainability comes from,
then you don’t just use AI – you understand it well enough to trust it.
About Data Mastery
Data Mastery focuses on building deep, practical understanding of data, analytics, and AI systems – from first principles to real-world application. No hype. No black boxes. Just clarity.

Leave a comment